

.png)
Récapitulation rapide : Le défi de l'hallucination
Le réviseur de code GenAI de Korbit analyse les demandes de téléchargement contenant des dizaines de milliers de lignes de code, mettant en évidence des milliers de problèmes potentiels allant de bogues mineurs à des vulnérabilités critiques en matière de sécurité.
Comme nous l'avons vu dans les parties I et II, les hallucinations constituent un obstacle important à ce processus : les problèmes signalés par les LLM n'existent pas en réalité ou ne peuvent tout simplement pas être traités par les développeurs. Ces faux positifs créent beaucoup de bruit et de frustration inutiles pour les équipes d'ingénieurs.
Précédemment, nous avons exploré la manière dont nous avons abordé le problème des hallucinations en développant une méthode de classification robuste utilisant la chaîne de pensée (CoT). Cette solution initiale, qui utilise GPT-4, a permis de détecter avec succès environ 45 % des hallucinations dans notre ensemble de données de test - une première étape prometteuse. Mais chez Korbit, le "suffisamment bon" n'est pas notre norme. Nous pensions qu'il y avait encore beaucoup à faire pour améliorer la situation.
Tirer parti des enseignements de plusieurs modèles
En analysant les erreurs de classification et en expérimentant différentes invites, nous avons remarqué quelque chose d'intriguant : De nombreuses hallucinations manquées par le modèle GPT-4 ont été correctement identifiées comme hallucinations par un autre modèle, Claude 3.5 Sonnet - même en utilisant exactement la même invite conçue pour le modèle GPT-4.
Cette constatation nous a amenés à nous demander si la combinaison de GPT-4 et de Claude 3.5 en un seul ensemble pourrait donner des résultats encore meilleurs.
Test d'approches d'ensemble simples
Nous avons décidé de tester les stratégies d'ensemble les plus simples possibles, afin de valider rapidement notre intuition :
- L'"Ensemble OR" : Si le GPT-4 ou Claude 3.5 signale une question comme une hallucination, nous la classons comme une hallucination.
- L'ensemble "ET" : Nous ne classons une question comme une hallucination que si le GPT-4 et Claude 3.5 sont d'accord.
Voici comment ces approches se sont comportées sur notre ensemble de données de test :
Tableau 1. Évaluation des performances
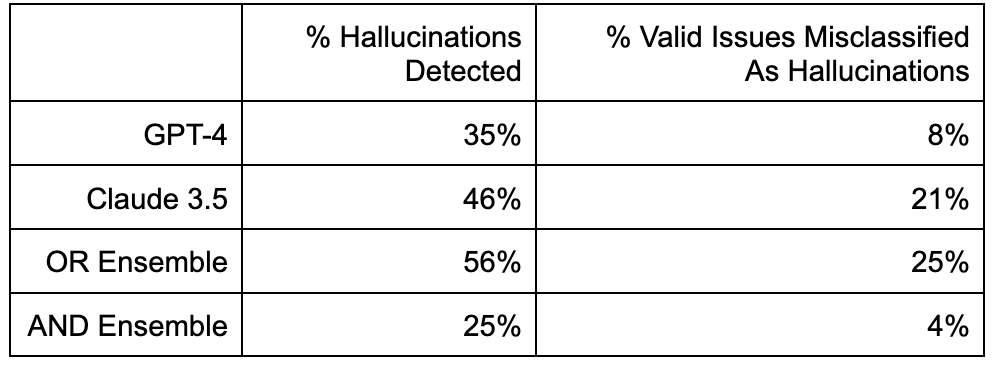
L'ensemble OR a maximisé le rappel, détectant 56 % de toutes les hallucinations, mais au prix d'un bruit plus élevé, classant par erreur 25 % des problèmes valides comme des hallucinations (faux positifs).
À l'inverse, l'ensemble AND a fait preuve d'une précision exceptionnelle, se trompant rarement dans la classification des problèmes valables, mais il s'est montré trop conservateur, ne retenant que 25 % de toutes les hallucinations.
Approfondir la question des classifications erronées
Lorsque nous avons examiné de près les erreurs de classification de l'ensemble OR, nous avons identifié deux catégories claires :
- Absence de contexte suffisant : Les modèles n'ont tout simplement pas eu accès aux informations nécessaires (par exemple, un fichier connexe dans la base de données), ce qui les a contraints à des jugements incertains.
- Pinailles stylistiques mineures ou à la limite de l'acceptable : Il s'agit de suggestions triviales et subjectives concernant le style de codage ou des questions mineures de remaniement, qui n'ont que peu de valeur dans le monde réel et qui agacent souvent les développeurs.
Au vu des réactions de nos clients, il est apparu clairement que nous devions nous concentrer sur la résolution de la première catégorie - les hallucinations dues à l'absence de contexte. Les petits détails stylistiques peuvent être ignorés, car ils ne font souvent que contribuer à un bruit inutile.
Après mûre réflexion, nous avons décidé de ne pas nous préoccuper outre mesure du deuxième type d'erreurs, liées à des points de détail et à des problèmes limites. Ces problèmes ont tendance à n'apporter que peu ou pas de valeur ajoutée aux clients - des clients qui, soit dit en passant, nous disaient déjà que notre produit soulevait trop de problèmes et qu'ils voulaient que nous réduisions le niveau de bruit.
Nous avons donc décidé de nous concentrer sur les erreurs causées par un manque de contexte - en particulier le cas où le MLD avait besoin d'accéder à d'autres fichiers de code source de la base de code.
Nous disposions d'un signal important pour nous aider dans cette tâche. Rappelez-vous de notre article de blog de la partie II que le LLM produit soit "Question valable", soit "Hallucination", soit "Indéterminé". La dernière étiquette "Indéterminé" est un signal très fort qui indique que le LLM a besoin d'accéder à un contexte supplémentaire pour effectuer une évaluation précise.
Nous nous sommes donc posé la question : Et si, dans les cas "indéterminés", nous demandions au MLD de quel autre dossier il a besoin pour évaluer la question, puis si nous réévaluions la question en fonction de ce contexte ?
Cela nous a amenés à construire un système d'ensemble multi-hop :
- Étape 1. Évaluer le problème avec GPT-4 et Claude 3.5 Sonnet :
- Si l'un des MFR indique "Indéterminé", passez à l'étape 2.
- Dans le cas contraire, si l'un des LLM produit "Hallucination", il attribue l'étiquette "Hallucination",
- Dans le cas contraire, attribuer l'étiquette "Question valable".
- Étape 2. Demander au LLM un chemin d'accès à un fichier contenant un contexte supplémentaire pertinent :
- Le mécanisme d'apprentissage tout au long de la vie qui a précédemment émis la mention "Indéterminé" est interrogé ici.
- Le LLM doit produire un objet JSON contenant un chemin d'accès au fichier, qui est ensuite comparé à un fichier réel dans le référentiel à l'aide d'un algorithme de correspondance de chaînes de caractères.
- Si le LLM produit un chemin non valide ou vide, attribuez l'étiquette "Question valide" afin d'éviter de filtrer incorrectement les questions valides. Sinon, passez à l'étape 3.
- Étape 3. Réévaluer le problème en fournissant le contenu du fichier supplémentaire à GPT-4 et Claude 3.5 Sonnet et en leur demandant de le réévaluer :
- Si l'un des LLM produit "Hallucination", attribuez-lui l'étiquette "Hallucination",
- Dans le cas contraire, attribuer l'étiquette "Question valable".
Le système est illustré dans l'organigramme suivant :
Figure 1. Système de détection des hallucinations
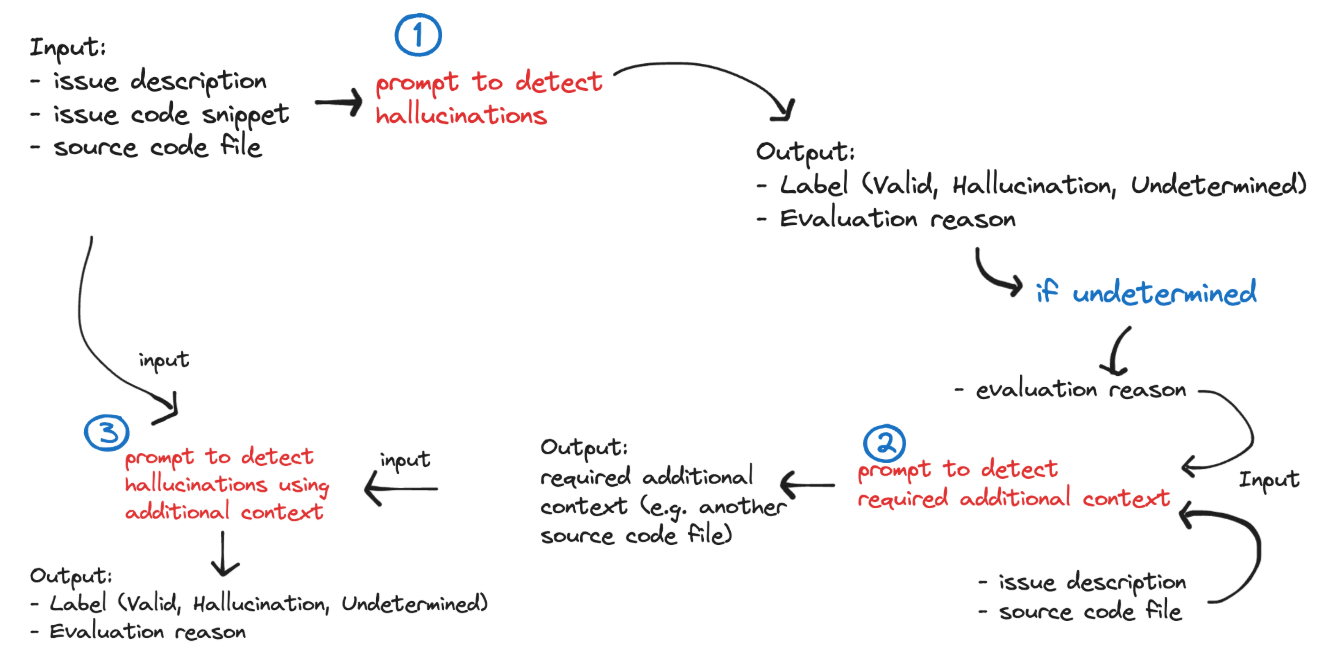
Ce système a considérablement augmenté les performances du système (en particulier, le rappel des hallucinations) comme nous le montrerons plus tard. Nous avons expérimenté d'autres variantes de ce système, y compris l'augmentation du nombre de sauts pour fournir un contexte de fichier supplémentaire au LLM, mais le système le plus performant est resté le système à trois sauts. Comme c'est souvent le cas, l'ajout de trop de contexte à un LLM peut souvent diminuer les performances - surtout si la plupart de ce contexte n'est pas pertinent !
Exemple : Détection d'un bogue halluciné dans LangChain
Prenons un exemple concret : le système a détecté et supprimé une hallucination dans un dépôt populaire de logiciels libres.
Voici un exemple de PR LangChain que nous avons analysé dans le cadre de notre analyse comparative :
https://github.com/langchain-ai/langchainjs/pull/2832
Dans ce rapport, Korbit a détecté le problème potentiel suivant, qui s'est avéré être une hallucination :
Tableau 2. Description du problème
OpenAIEmbeddings est instancié sans clé API, ce qui entraînera des échecs d'exécution.
Figure 2. Capture d'écran du code du référentiel LangChain
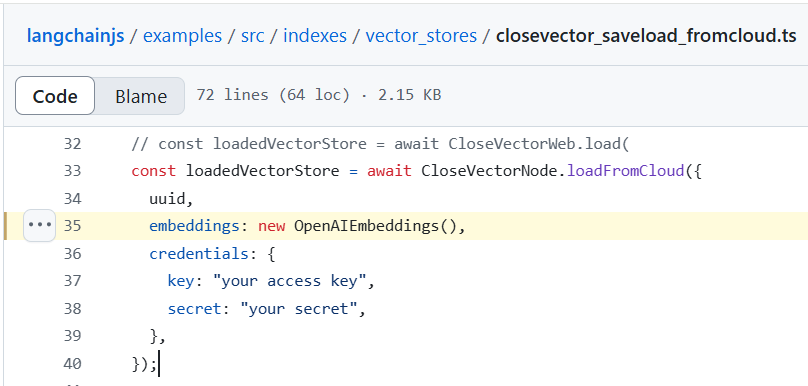
Il s'agit d'une hallucination car la fonction d'initialisation d'OpenAIEmbeddings gère la clé d'authentification. Il n'y aura donc pas d'erreurs d'exécution. Nous le savons, mais le modèle ne le sait pas. Le montrer au développeur lui fait perdre du temps et crée de la frustration.
Ce problème (ainsi que tous les autres problèmes détectés dans le PR) a été confié au détecteur d'hallucinations. Dans un premier temps, il a extrait le contenu du fichier actuel dans lequel le problème a été détecté, puis a utilisé Chain of Thought pour interroger à la fois GPT-4o et Claude 3.5 afin d'évaluer le problème.
Examinons les résultats de GPT-4o pour la première étape de l'algorithme :
Tableau 3. Sortie GPT-4o : 1ère étape
{
"question_1" : "L'instanciation d'OpenAIEmbeddings se fait-elle sans fournir de clé API dans l'une ou l'autre des instances du code ?",
"answer_1" : "Oui, l'instanciation d'OpenAIEmbeddings à plusieurs endroits comme 'new OpenAIEmbeddings()' ne montre pas qu'une clé API est fournie",
"question_2" : "OpenAIEmbeddings nécessite-t-il une clé API pour fonctionner correctement au moment de l'exécution ?",
"answer_2" : "Généralement, les services comme OpenAI nécessitent des clés API pour l'authentification afin d'accéder à leurs services.",
"question_3" : "La documentation ou les commentaires indiquent-ils qu'il est nécessaire de fournir une clé API pour OpenAIEmbeddings ?",
"answer_3" : "Les extraits fournis ne mentionnent pas explicitement la nécessité d'inclure une clé API pour OpenAIEmbeddings",
"évaluation" : "Question valable",
"evaluation_reason" : "L'instanciation d'OpenAIEmbeddings sans clé API est susceptible de provoquer des problèmes d'exécution, car ces services nécessitent généralement une authentification via des clés API."
}
Remarquez que le modèle pose d'abord correctement la question de l'API et conclut qu'elle n'est donnée nulle part. Si vous lisez le code source, vous verrez qu'elle n'est effectivement donnée nulle part dans ce fichier. Il raisonne ensuite sur la question de savoir si les clés d'API sont typiquement nécessaires, et conclut à nouveau qu'elles sont typiquement nécessaires.
Enfin, il conclut que "l'instanciation d'OpenAIEmbeddings sans clé API est susceptible de provoquer des problèmes d'exécution, car ces services nécessitent généralement une authentification via des clés API". Si tout ce que le modèle peut voir est le contenu actuel du fichier, cette conclusion semble assez raisonnable, bien qu'elle s'avère finalement incorrecte puisque la clé API est définie ailleurs. Ainsi, si nous n'avions interrogé que GPT-4o, l'évaluation aurait été que ce problème est valide et il aurait été montré au développeur - ce qui aurait causé de la frustration et de la douleur. Heureusement, le système est un système d'ensemble qui comporte de multiples contrôles et équilibres pour gérer exactement ce type de situation.
Examinons maintenant le résultat de Claude 3.5 :
Tableau 4. Claude 3.5 Sortie : 1ère étape
{
"question_1" : "OpenAIEmbeddings est-il instancié sans clé API dans le code ?",
"answer_1" : "Oui, OpenAIEmbeddings est instancié sans clé API explicite dans l'extrait de code fourni",
"question_2" : "Existe-t-il d'autres configurations ou variables d'environnement susceptibles de fournir la clé API ?",
"answer_2" : "Le code ne montre aucune configuration de variable d'environnement ou d'autres configurations pour la clé API. Cependant, il est possible que la clé API soit configurée ailleurs dans le projet ou l'environnement, ce que nous ne pouvons pas déterminer à partir de ce seul extrait.",
"question_3" : "Le code présente-t-il des signes d'échecs d'exécution dus à une clé API manquante ?",
"answer_3" : "Le code ne présente aucune gestion d'erreur ni aucun signe d'échec d'exécution. Il semble utiliser l'instance OpenAIEmbeddings sans aucun problème à plusieurs endroits",
"évaluation" : "Indéterminé",
"evaluation_reason" : "S'il est vrai que l'OpenAIEmbeddings est instancié sans clé API explicite dans le code visible, nous ne pouvons pas affirmer avec certitude que cela entraînera des échecs d'exécution. La clé API peut être configurée dans l'environnement ou ailleurs dans le projet. De plus, le code ne montre aucun signe d'échec dû à une clé API manquante. Sans plus de contexte sur la configuration du projet et le comportement de l'exécution, nous ne pouvons pas déterminer de manière concluante s'il s'agit d'un problème valide ou d'une hallucination".
}
Le raisonnement de la chaîne de pensée donné par Claude 3.5 est similaire à GPT-4o pour la première partie, mais diverge à la fin lorsqu'il demande "Le code montre-t-il des signes d'échecs d'exécution dus à une clé d'API manquante ? Il justifie et répond à sa propre question en disant "Il semble utiliser l'instance OpenAIEmbeddings sans aucun problème à plusieurs endroits". Ainsi, le fait qu'il observe le même modèle plusieurs fois dans la base de code l'amène à penser qu'il ne s'agit probablement pas d'un problème d'exécution - bien qu'il ne puisse pas le savoir avec certitude. Enfin, il conclut que le problème est "indéterminé", ce qui est vraiment le mieux que le système ait pu faire compte tenu de son contexte limité.
Cela déclenche à son tour l'étape suivante de l'algorithme, qui consiste à rechercher un contexte supplémentaire dans le reste de la base de code. À tout moment, si l'un des modèles classe un problème comme "indéterminé", le détecteur d'hallucinations passera à la deuxième phase, qui consiste à rechercher du contexte supplémentaire dans d'autres fichiers et à réévaluer le problème en question. Mieux vaut prévenir que guérir !
Le détecteur d'hallucinations interroge Claude 3.5 pour identifier des sorties contextuelles supplémentaires :
Tableau 5. Claude 3.5 Sortie : 2ème étape
{
"class_name" : "OpenAIEmbeddings",
"file_name" : "openai.ts",
"file_path" : "langchain/src/embeddings/openai.ts"
}
Ce fichier est associé au fichier examples/src/embeddings/openai.ts, qui montre un autre exemple d'initialisation d'OpenAIEmbeddings dans la base de données :
Figure 3 : Fichier src/embeddings/openai.ts Fichier src/embeddings/openai.ts
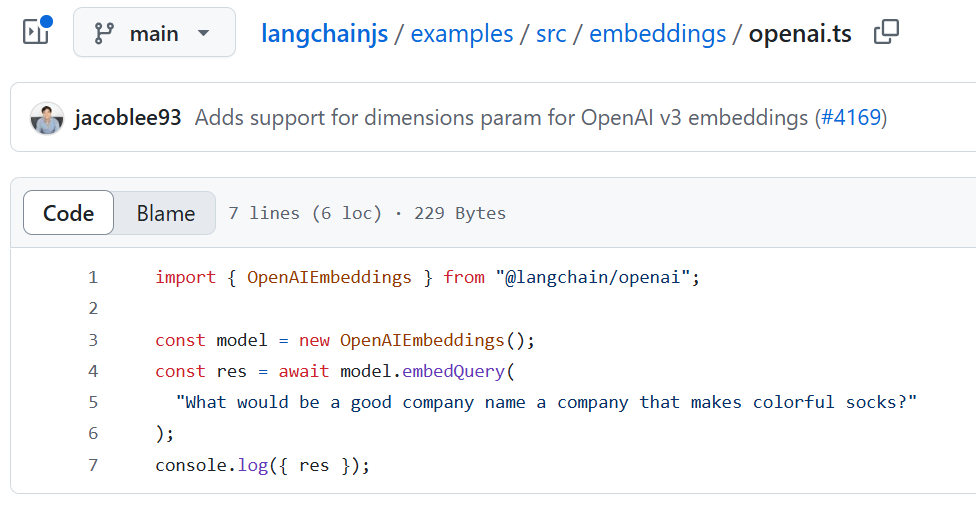
Le fichier ne montre pas où l'API est définie, mais il fournit des preuves supplémentaires aux LLM montrant que l'approche typique est d'effectuer une initialisation sans fournir de clés API.
Enfin, le contenu de ce nouveau fichier est transmis à la fois à GPT-4o et à Claude 3.5 pour qu'ils réévaluent le problème. Voici la réponse de GPT-4o :
Tableau 6. Sortie GPT-4o : 3e étape
{
"question_1" : "Is there any evidence in the code that the OpenAIEmbeddings class requires an API key during instantiation ?" (Y a-t-il des preuves dans le code que la classe OpenAIEmbeddings nécessite une clé API lors de l'instanciation),
"answer_1" : "Non, le code fourni ne montre aucune exigence ou paramètre pour une clé API lors de l'instanciation d'OpenAIEmbeddings.",
"question_2" : "L'instance OpenAIEmbeddings est-elle utilisée d'une manière qui nécessite une clé API plus loin dans le code ?",
"answer_2" : "Non, l'utilisation d'OpenAIEmbeddings dans le code n'indique pas la nécessité d'une clé API. Les informations d'identification sont utilisées lors de l'enregistrement ou du chargement du magasin de vecteurs vers ou depuis le nuage, et non lors de la création de l'instance d'OpenAIEmbeddings.",
"question_3" : "Le paramètre d'initialisation de la classe OpenAIEmbeddings correspond-il à un autre contexte de code indiquant un problème lié au fait de ne pas fournir de clé API ?",
"answer_3" : "No, there are no indications in the provided code context that initializing OpenAIEmbeddings without an API key is problematic or will cause runtime failures",
"évaluation" : "Hallucination"
}
Le modèle a correctement conclu que "... il n'y a aucune indication dans le contexte du code fourni que l'initialisation d'OpenAIEmbeddings sans une clé API est problématique ou causera des échecs d'exécution". Par conséquent, il a ensuite classé le problème original comme une "hallucination".
Ce résultat est déjà suffisant pour conclure que le problème est une hallucination et pour le supprimer. Cependant, jetons également un coup d'œil sur les résultats de Claude 3.5 ici :
Tableau 7. Sortie Claude 3.5 : 3ème étape
{
"question_1" : "OpenAIEmbeddings est-il instancié dans le code sans fournir de clé API ?",
"answer_1" : "Oui, OpenAIEmbeddings est instancié sans clé API explicite dans les extraits de code présentés",
"question_2" : "Existe-t-il d'autres façons de fournir la clé API qui ne seraient pas visibles dans cet extrait de code ?",
"answer_2" : "Oui, il peut y avoir d'autres moyens de fournir la clé API, comme des variables d'environnement ou des fichiers de configuration, qui ne sont pas visibles dans cet extrait de code",
"question_3" : "Le code présente-t-il des signes de gestion des erreurs ou de configuration qui pourraient suggérer que la clé API est gérée ailleurs ?",
"answer_3" : "Non, le code ne montre pas de gestion d'erreur explicite ou de configuration liée à la clé API OpenAI. Cependant, le code inclut la gestion des informations d'identification pour CloseVector, ce qui suggère que les clés API pourraient être gérées de la même manière pour OpenAI.",
"évaluation" : "Indéterminé"
}
Claude 3.5 a examiné le code supplémentaire fourni et a conclu à nouveau que le problème était "indéterminé". Cela aurait également été suffisant pour supprimer le problème, ou du moins pour l'empêcher d'être montré au développeur.
Un système d'ensemble détecte près de 80 % des hallucinations
Les résultats suivants concernent deux ensembles de données de référence (n=328 questions au total)
Tableau 8. Performances sur deux ensembles de données de référence (n=328 problèmes au total)
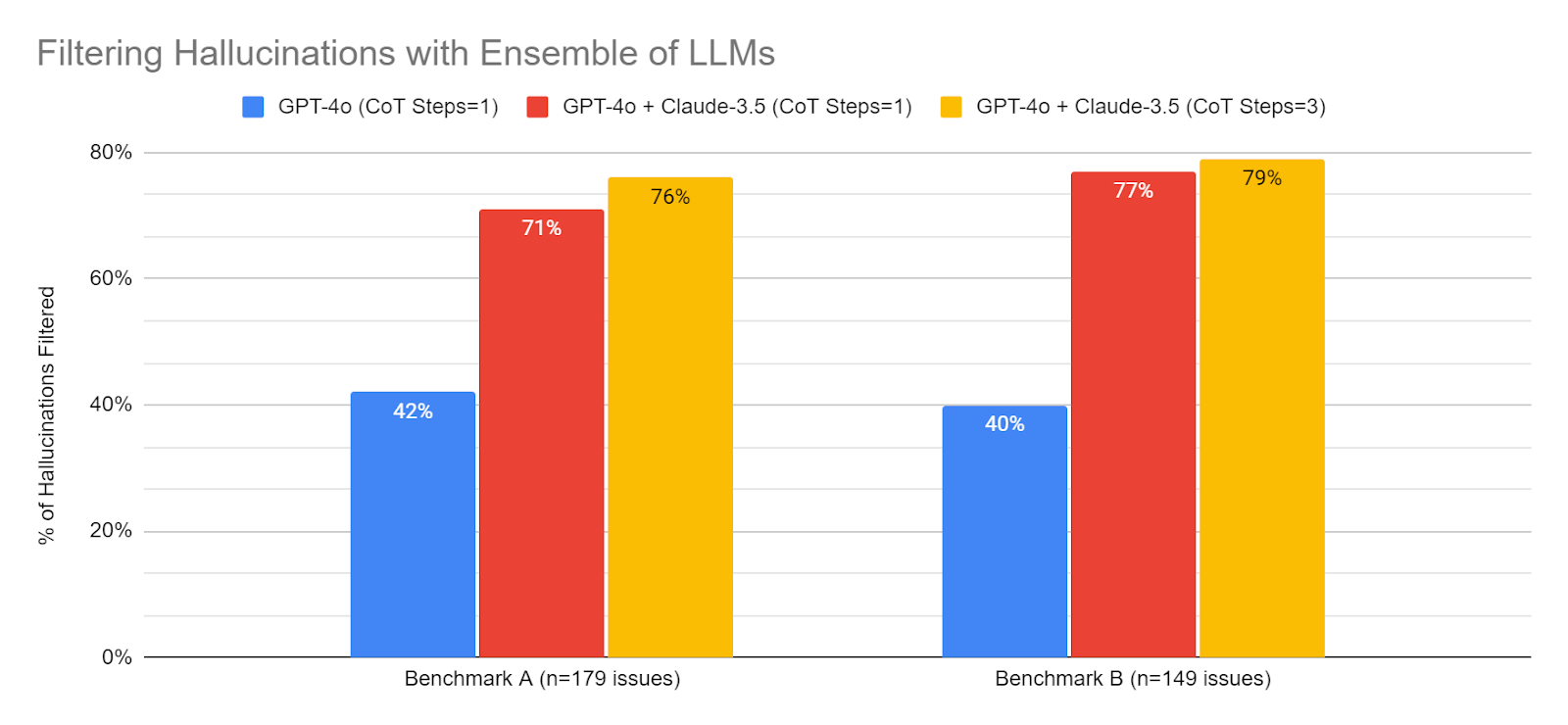
Comme le montrent les résultats, en combinant la technique CoT avec un ensemble et un système à sauts multiples, nous sommes désormais en mesure de détecter près de 80 % de toutes les hallucinations. C'est une grande victoire pour nous, car cela réduit considérablement le problème des hallucinations dans le système - réduisant ainsi la frustration et la douleur de nos nombreux clients et développeurs qui utilisent Korbit.
En outre, nous avons examiné manuellement les quelques problèmes valables que le système avait incorrectement qualifiés d'"hallucination" (c'est-à-dire de faux positifs). La majorité de ces problèmes étaient des pinaillages mineurs et des problèmes limites qui, selon nous, n'auraient pas d'impact négatif significatif sur la valeur pour les clients - en fait, de nombreux clients préféreraient probablement mettre ces problèmes en sourdine.
La mise en place de ce système a nécessité des semaines de travail impliquant l'examen et l'annotation des problèmes, la collecte d'ensembles de données, l'ingénierie des systèmes et des messages, suivies de la mise en œuvre finale dans notre système de production - mais cela s'est traduit par une grande victoire pour nous et pour nos clients !



